Abstract
This paper explores the deployment and challenges of Reinforcement Learning (RL) and Deep Reinforcement Learning (DRL) for precision angle seeking in robotic control across both simulated and physical environments. We introduce the Angular Positioning Seeker (APS) environment, leveraging Raspberry Pi 4B+ platforms to rigorously evaluate RL algorithms in scenarios that closely mimic real-world conditions. This benchmark highlights the subtleties distinguishing RL implementations in physical realms from simulated proxies, fostering advancements and more nuanced testing protocols within the domain of robotic intelligence.
Method
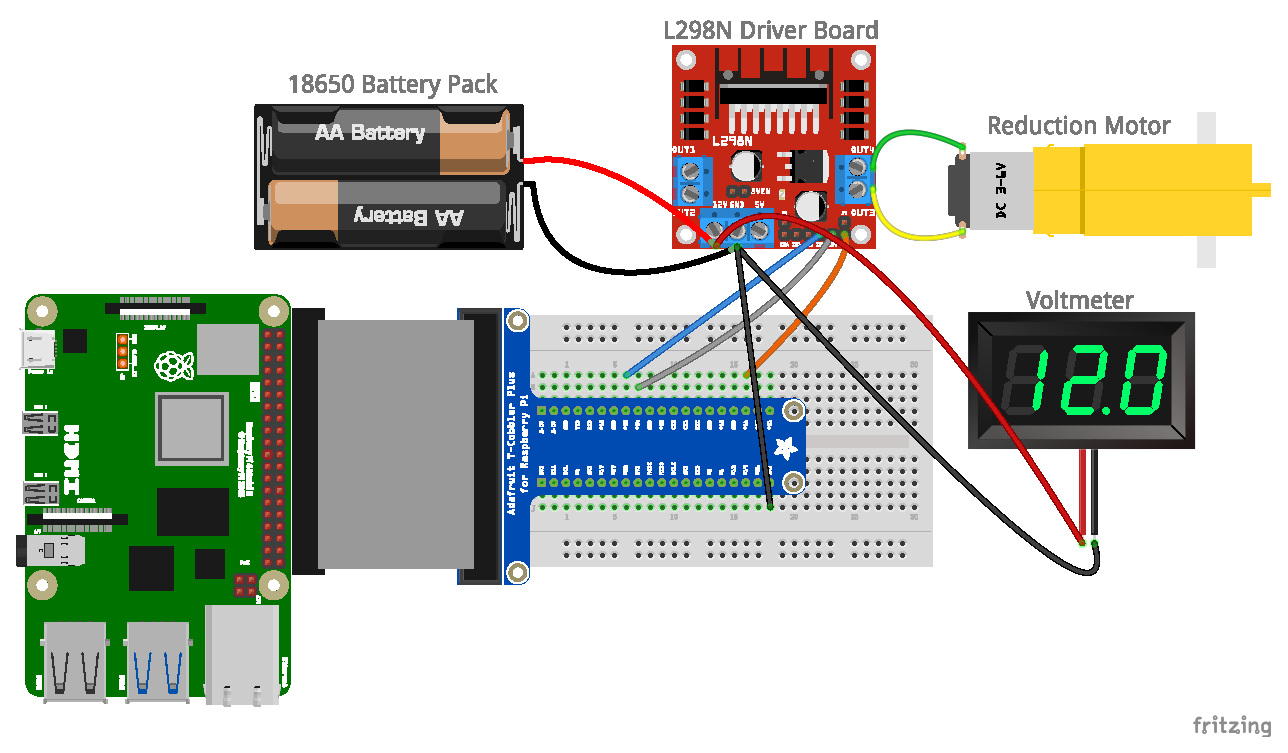
In the methodology, we developed the Angular Positioning Seeker (APS) environment using OpenAI’s Gym tailored for angular positioning tasks and implemented the step function logic prioritizing angle-seeking behavior. We utilized Raspberry Pi 4B+ and STM32F103ZET6 microcontrollers to construct a physical apparatus, ensuring robust evaluation of RL algorithms. The DQN algorithm and its variants, including Double DQN and Dueling DQN, were applied in both simulated and physical settings. The system's performance was measured using reward functions designed to minimize deviation from target angles, with detailed pseudocode provided for reproducibility.